Overview
I got some feedback after my original post that it would be tedious maintaining a DynamoDB table for agent extensions. I wanted to make a complete solution and decided it would be a fun project to automate maintenance of the table. First thing I had to redesign the table to keep track of unused extensions. Then I made another Lambda in Python that updated the table when triggered by a scheduled EventBridge Event. Once I was done I wanted to make it easy to deploy. While looking into using CloudFormation to do this I learned about aws sam. Sam makes it a little easier to make CloudFormation templates for serverless apps and packages it up nicely for you. I wrote up a sam template and got the project published in the Serverless Application Repository The whole thing took awhile but I really enjoyed getting more experience with these aws services while I study for my developer associate. Plenty to talk about with everything that went into the project so I’ll probably end up making a few posts about it. In this post I’ll focus on how I redesigned the DynamoDB table.
Designing the Table
I didn’t go into this with much knowledge of how DynamoDB/NoSQL worked.
Luckily this awesome presentation by Rick Houlihan really helped me understand how it differs from SQL and how to design a schema with that in mind.
I was really excited by the idea of single table design and the scalability of NoSQL.
Originally I wanted to add routing profile history for each agent and routing profile information like associated queues and number of associated agents. I decided to hold off since the Connect API currently throttles at 2 requests per second for requests other than GetMetricData and GetCurrentMetricData without a service limit increase.
Even with the table only holding agent extension data I still needed a GSI to be able to query by agent and unused extensions.
My end result was a table for querying by extension.
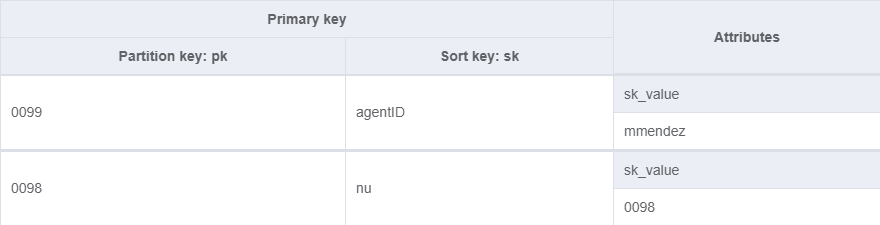
And a GSI for querying by username or unused nu extensions.
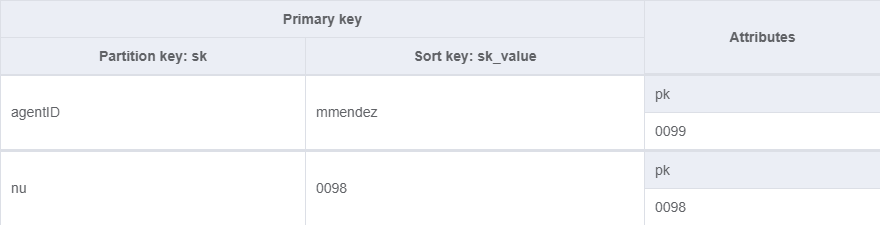
Generally I think it would make more sense to use agentID as the primary key.
If you add more attributes to agent items down the road, such as a routing_profileor even non_productive_time, then most of the time you’d probably want to query by the agentID and not extension. I use those attribute names as examples; attribute names should be concise to keep table size low.
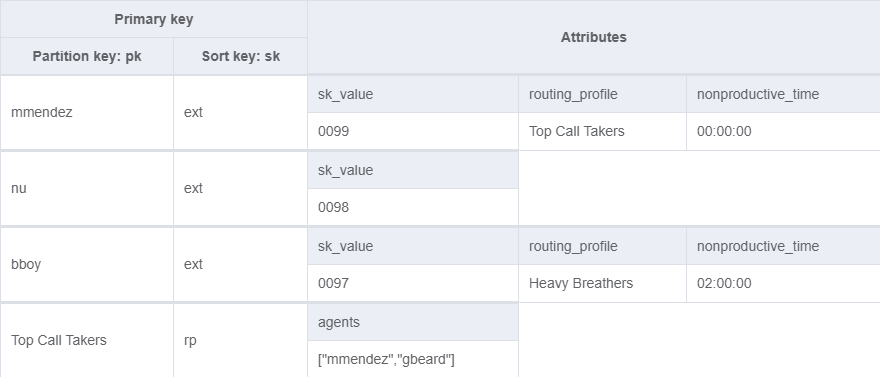
This is an example of what the table could look like if we started consuming data from agent streams to track agent activity. What’s really cool is that since NoSQL is basically just a giant hash table, we get very fast lookup, even when the table is huge. We just have to make sure we’re using primary keys that evenly distribute all of our access patterns. So realistically we could store weeks of agent activity, routing profiles, contact trace records, and all the information related to them in a single table with the right design.
I’ll go into the new Lambda function in my next post.